Optimiser la taille de la base de données de Home Assistant
Si on ne fait pas attention, la base de données Home Assistant peut rapidement devenir obèse avec plusieurs centaines de méga-octets. Il est probable qu’elle stocke beaucoup d’information qui n’est pas utile à conserver. Voici quelques trucs pour identifier et réduire à ce qui vous intéresse.
Comprendre ce qui est stocké
Il y a plusieurs espaces de stockage sous Home Assistant:
- la configuration de vos entités et intégration gérée par Home Assistant, sous forme d’une collection de fichiers json dans
/config/.storage(en complément des éventuels yaml de configuration dans/config) - l’historique des états de vos entités, gérée par le
Recorderde Home Assistant ; par défaut il va stocker dans une base SQLite dans le fichier/config/home-assistant_v2.db(d’autres bases sont supportées, ou des recorder spécialisées, mais c’est en dehors du scope de cet article). Ce recorder stocke plusieurs choses :- l’historique des états de vos entités (table
states) - lorsque les états ont des attributs, ceux-ci sont stockés dans une autre table
states_attributes; une nouvelle entrée n’est créée que lorsque les attributs changent pour optimiser le stockage ; c’est donc rarement un problème d’avoir de nombreux attributs lorsqu’ils sont tous stables, mais si un seul change (comme un simple timestamp) et c’est la porte ouverte à une forte inflation - ces états et attributs sont stockés seulement quelque jours, souvent 10 jours, passé ce délai les états et attributs sont supprimés, et suivant le type de capteur seuls des statistiques sont conservées, par exemple pour les sensors une valeur moyenne, min et max sue chaque période. Il y a des statistiques court terme (avec une granularité 5mn pour un historique très détaillé) et long terme (agrégées à l’heure).
- l’historique des états de vos entités (table
Les références pour tout comprendre :
Et pour suivre la taille de votre base, je vous conseille d’ajouter une entité File Size qui pointe sur votre fichier de base de données:
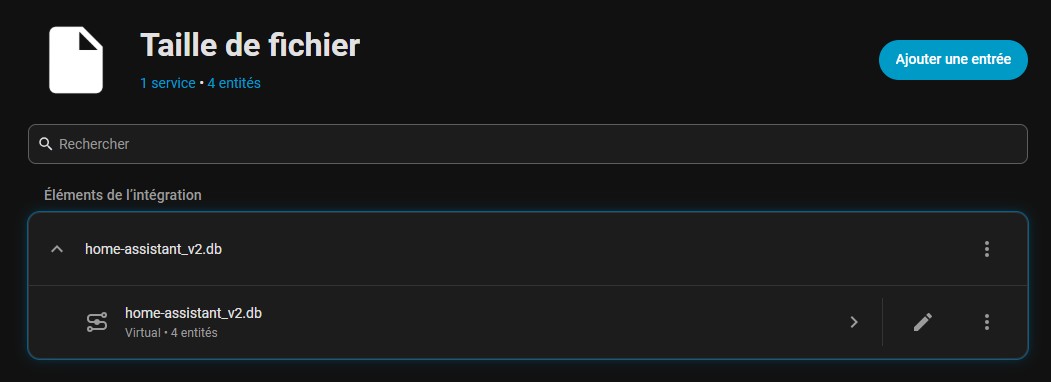
L’addon dbstats
Il existe un addon dbstats qui permet de faciliter la compréhension du contenu de la base. Cet addon est l’inspiration pour la suite de cet article, et déjà très utile, mais présente quelques inconvénients :
- les graphiques sont des images, il n’est pas possible de copier les identifiants des libellés pour les exclure du recorder
- les tables s’arrêtent aux premières valeurs
- les tables présentent souvent un nombre de lignes sans qu’il soit possible de se rendre compte de la taille occupée
- les tables présentent des éléments unitaires, mais il manque une vision de synthèse
Des requêtes custom utiles
J’ai donc créé quelques requêtes SQL pour me fournir une vision agrégée, à copier coller dans l’addon SQLite Web
Une requête pour voir la synthèse des états et attributs
SELECT
entity,
SUM(states_count) AS states_count,
SUM(attributes_count) AS attributes_count,
SUM(attributes_size) AS attributes_size
FROM (
-- Requête 1 : Nombre d'états par entité
SELECT
sm.entity_id AS entity,
COUNT(*) AS states_count,
0 AS attributes_count,
0 AS attributes_size
FROM states s
JOIN states_meta sm ON s.metadata_id = sm.metadata_id
WHERE s.last_updated_ts >= (strftime('%s', 'now') - 24*60*60)
GROUP BY sm.entity_id
UNION ALL
-- Requête 2 : Attributs par entité
SELECT
sm.entity_id AS entity,
0 AS states_count,
COUNT(*) AS attributes_count,
SUM(LENGTH(sa.shared_attrs)) AS attributes_size
FROM states s
JOIN states_meta sm ON s.metadata_id = sm.metadata_id
JOIN state_attributes sa ON sa.attributes_id = s.attributes_id
WHERE s.last_updated_ts >= (strftime('%s', 'now') - 24*60*60)
GROUP BY sm.entity_id
) AS requetes_combinees
GROUP BY entity
ORDER BY states_count + attributes_count DESC;
Une requête pour voir la taille des tables et index
-- See what tables/indexes are taking space
SELECT name, sum(pgsize)/1024/1024 as size
FROM dbstat
GROUP BY name
ORDER BY size DESC
Une requête pour voir les entités avec de nombreux états
-- List entities with lot of states
SELECT sm.entity_id as entity, count(*) as count
FROM states s, states_meta sm
WHERE s.metadata_id = sm.metadata_id
GROUP BY entity
ORDER BY count DESC
Cette requête n’est pas très exacte, car elle peut compter plusieurs fois un même groupe d’attributs, on verra plus tard comment compter de manière plus exacte.Une requête pour voir la taille des attributs
-- Get size of state attributes by entities
SELECT sm.entity_id as entity, sum(length(sa.shared_attrs)) as count
FROM states s, states_meta sm, state_attributes sa
WHERE s.metadata_id = sm.metadata_id
AND sa.attributes_id = s.attributes_id
GROUP BY entity
ORDER BY count DESC
Une requête pour voir les attributs d'une entité pour comprendre ce qui est stocké
-- Inspect attributes of an entity
SELECT DISTINCT sm.entity_id as entity, sa.attributes_id, sa.shared_attrs
FROM states s, states_meta sm, state_attributes sa
WHERE s.metadata_id = sm.metadata_id
AND sa.attributes_id = s.attributes_id
AND sm.entity_id = "device_tracker.capteur_fuite_eau"
RETEX du vibe-coding d’un addon
Après avoir itéré plusieurs voir sur ma base avec les requètes manuelles ci-dessus, ça m’a donné envie d’avoir quelque chose d’un peu plus industriel, dont la première expression de fonctionnalité a été
1er tableau: Liste des tables : Mo (est.)
2ème tableau: Liste des entités : nombre / attributs Mo (est.)
- si clic sur attributs, affichage des 10 derniers attributs
- si clic sur nombre, lien page historique
- si clic sur entité, lien page entité
Par ailleurs comme je n’avais encore jamais fait d’addon Home Assistant, et que j’étais en train d’expérimenter les possibilités de Github Copilot (avec simplement l’offre gratuite), je me suis dit que c’était une bonne occasion de vibe-coder l’application à partir de cette liste de requirements et des SQL ci-dessus, que j’ai un peu plus étoffée et ajouté quelques contraintes techniques pour éviter des frameworks et fichiers trop complexes. La première génération est assez bluffante, car on arrive littéralement à avoir en quelques minutes une première application qui ressemble à quelque chose, et quasi fonctionnelle. Comme je n’avais pas défini de tests, il y avait cependant quelques erreurs de calcul que j’ai du lui demande de refaire. Et c’est assez addictif, on se retrouve très facilement à ajouter des fonctionnalités, et itérer pour avoir exactement ce que l’on veut. Au fur et à mesure, le code perd en simplicité et en cohérence, car Github Copilot va plus facilement générer du spécifique que du générique réutilisé, ou pas forcément comme on l’aurait fait. J’imagine qu’il faudrait que je lui fasse faire des tests et réécrire intégralement sur la base des requirements actualisés et tests, mais c’est la limite de l’offre gratuite Github Copilot et ses quotas un peu bas. Bref, une première expérience de vibe-coding intéressante, je ne me serais sans doute pas lancé dans cet addon sans ça.
Et sinon la documentation officielle pour développer un addon/app HomeAssistant
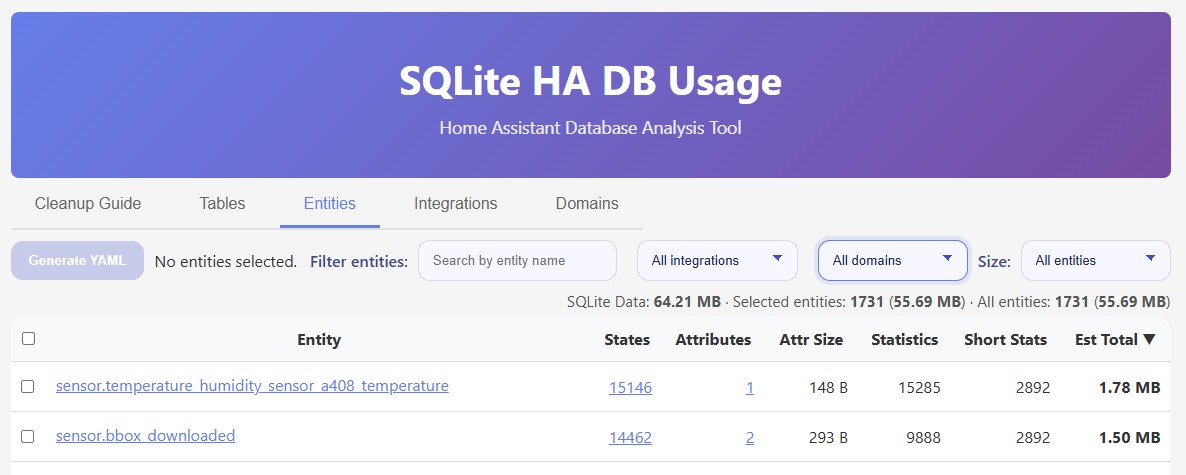
L’addon SQLite HA DB Usage
Le résultat est disponible dans ce repo github.com/rpeyron/ha-dbusage. Il suffit de suivre les instructions d’installation sur la page.
Le grand ménage
Cet addon vous permet maintenant de bien identifier les sources de ce qui prend de la place, et:
- soit de désactiver les extensions qui ne vous seraient plus utiles mais génère beaucoup d’entités ou de grande tailles
- soit d’exclure ce qui prend de la place et qui n’est pas nécessaire à conserver
A noter qu’à ce jour le paramétrage du recorder est assez basique, et qu’il n’est pas possible d’exclure simplement toute une extension, ou seulement le stockage long terme, ou d’avoir une durée de rétention différente par entités / type d’entité. Egalement, un petit piège, dès qu’on utilise include alors l’enregistrement par défaut disparait et seules les entités inclues sont enregistrées. Il n’est donc pas possible d’utiliser un exclude_globs et un include pour réinclure une entité qui aurait été exclue. Vous pouvez bien sûr choisir de n’inclure que les entités que vous souhaitez, mais c’est facile d’oublier donc j’ai préféré conserver l’enregistrement par défaut et des exclusions.
L’usage du plugin permet de selectionner les entités et de générer le code yaml de configuration à compier coller dans configuration.yaml.
Pour ma part je généralise souvent les entités trouvées dans des globs sur les patterns associés ; par exemple un extrait de ma configuration:
recorder:
exclude:
entity_globs:
- media_player.*
- camera.*_stream
- sensor.*_uptime*
À noter la très agaçante traduction des identifiants d’entités, qui n’est pas non plus consistante, il faut souvent déclarer les patterns dans les deux langues.et d'autres exemples
# Portainer
- sensor.*_cpu_usage_total*
- sensor.*_memory_limit*
- sensor.*_memory_usage*
- sensor.*_memory_usage_percentage*
- sensor.*_du_processeur*
- sensor.*_du_disque*
- sensor.*_de_la_memoire*
- sensor.*_image
# ZHA
- sensor.*_rssi
- sensor.*_niveau_de_signal
- sensor.*_battery
- sensor.*_battery_level
- sensor.*_batterie
# Proxmox
- sensor.*_utilisation_maximale_du_disque
- sensor.*_utilisation_maximale_de_la_memoire
- sensor.*_backup_duration
- sensor.storage_*_usage_percentage
- sensor.storage_*_storage
- sensor.storage_*_available_storage
- sensor.storage_*_total_storage
- sensor.*_network_input
- sensor.*_network_output
Pour aller jusqu’au bout du cleanup, il faut quelques étapes manuelles, pour d’une part purger les entités, et d’autre part supprimer également les statistiques.
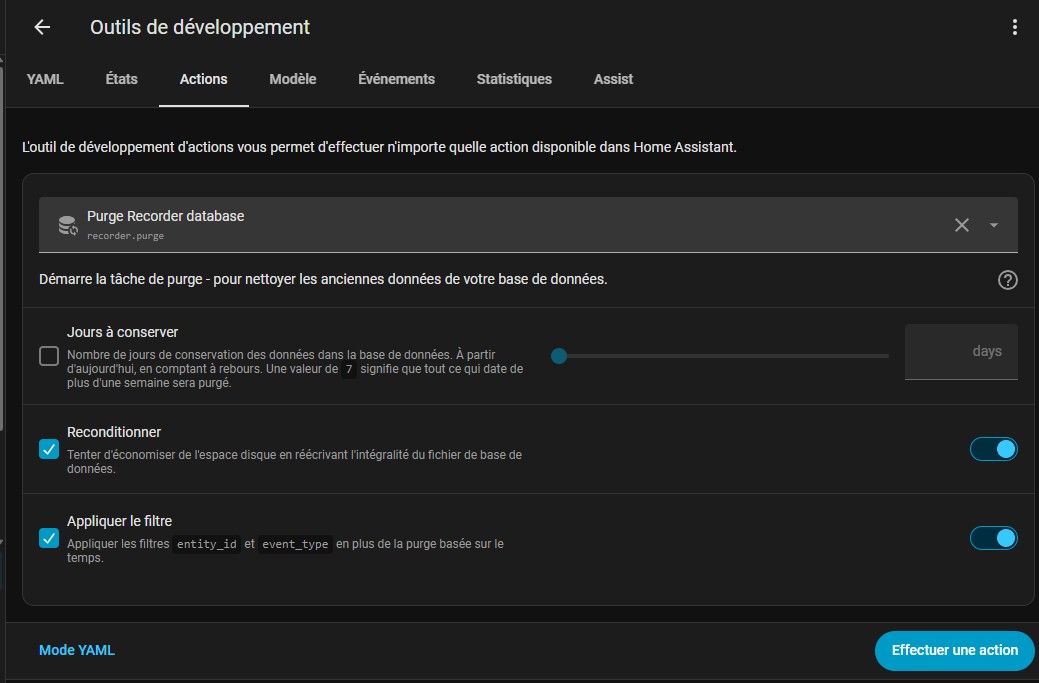
Pour prendre en compte vos nouvelles exclusions, soit vous êtes patients et vous attendez 15 jours que les purges automatiques fasse le travail, soit vous le faites manuellement, via les outils de développement et l’action recorder.purge ; il faut bien cocher sur les 2 cases à cocher appliquer le filtre (supprimer directement vos nouvelles exclusions), et le reconditionnement (ce qui va réécrire le fichier SQLite pour le réduire à la taille minimum des données utilisées)
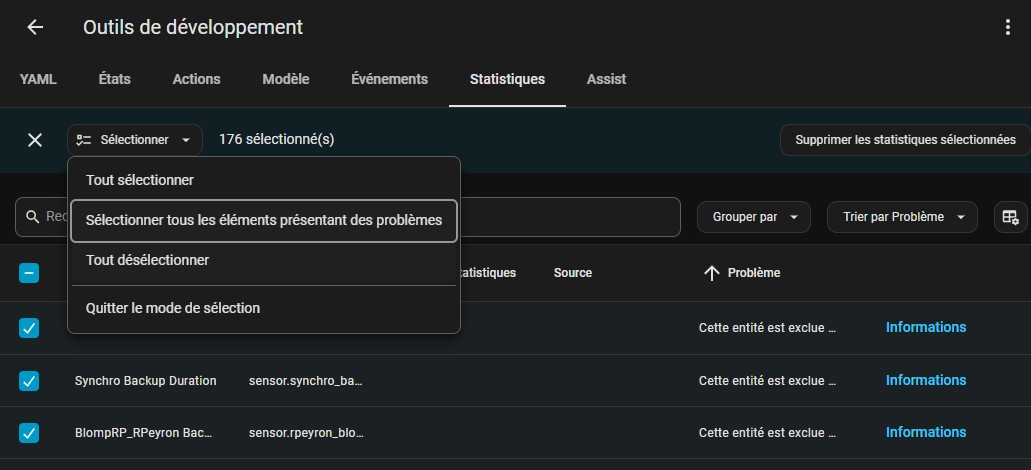
Enfin, la purge, qu’elle soit manuelle ou automatique, ne supprime pas les statistiques. Pour ce faire, on va utiliser le menu Statistiques dans les outils de développements, et sélectionner toutes les entités avec “problèmes”. Comme la purge supprime les états des entités, elles vont automatiquement apparaitre ici. Bien relire la liste des entités sélectionner pour vérifier qu’il n’y a pas d’autres entités avec des problèmes d’intégration passagers et qu’on ne voudrait pas supprimer.
Résultat, une base divisée par cinq !
Au fur et à mesure de mes optimisations, installations de nouvelles intégrations, nouvelles optimisations… j’ai pu diviser la taille de ma base de donnée par 5 !
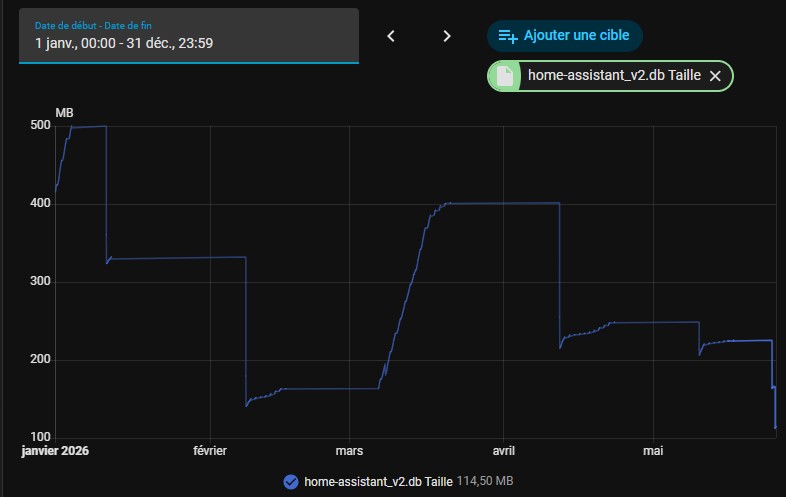
Au quotidien ça ne change pas grand-chose, mais c’est notamment appréciable pour les sauvegardes multiples qui avaient fini par saturer le disque.
Bonus : SQL pour fusionner l’historique de deux capteurs
La meilleure solution pour fusionner l’historique est de renommer l’entité du nouveau capteur en celui de l’ancien capteur via le paramétrage de l’entité. Cela permettra à cette nouvelle entité d’hériter automatiquement de l’historique de l’entité précédente. Si toutefois ce n’est pas possible, typiquement pour celles générées automatiquement depuis des intégrations type MQTT, alors un petit script SQL peut résoudre le problème.
Attention, le script correspond à l’usage dont j’avais besoin, sur les statistiques long terme, mais ne couvre pas toutes les tables de la base de données. À utiliser avec précautions !! Notamment il faut que les plages de dates des statistiques à merger soient disjointes. Si ce n’est pas le cas, vous pouvez supprimer la partie de redondance avant le merge.
-- Step 1: identifier les statistics_id source et cible (et via l'IHM)
SELECT * FROM "statistics_meta" WHERE statistic_id LIKE '%puissance%'
-- Step 2: vérifier
SELECT * FROM states
WHERE last_updated_ts BETWEEN strftime('%s', '2025-12-07 19:00:00') AND strftime('%s','2026-01-24 17:22:00')
AND metadata_id = 895
-- Step 3: changer l'identifiant
UPDATE states SET metadata_id = <id_cible>
WHERE last_updated_ts BETWEEN strftime('%s', '2025-12-07 19:00:00') AND strftime('%s','2026-01-24 17:22:00')
AND metadata_id = <id_source>

Domoticz – Panasonic remote buttons and Custom URLs
There is no need to introduce the great home automation software Domoticz and I wrote already some blog posts about it. Today I pushed a pull request to the Domoticz GitHub to add two features I was missing :


Un écran tactile autonome Home Assistant avec un Raspberry Pi Zero 1
Je souhaitais un moniteur Home Assistant indépendant et tactile. Il existe de nombreuses méthodes plus ou moins simples. Les méthodes qui semblent les plus simples passent par l’utilisation d’une tablette Android et d’un navigateur en mode Kiosque (exemple sur cet article avec la tablette Blackview Tab90, 140€ pour 11 pouces)....

Zigbee sous Home Assistant avec la box LIDL (Silvercrest TYGWZ-01)
À l’occasion d’une promotion chez Lidl j’ai acheté une box Zigbee Silvercrest à moins de 10 euros, un peu au pif compte tenu du faible prix, et dans l’idée d’ajouter une interface Zigbee à mon installation domotique Home Assistant. Pas si simple, mais finalement une bonne affaire.

Intégration de statistiques Piwik Pro (Custom card et sensor command_line)
Home Assistant est extensible très facilement, et permet d’intégrer donc de nouvelles sources. Cet article permet de montrer comment ajouter des reports Piwik Pro (web analytics) dans un dashboard Home Assistant, et également des capteurs virtuels pour récupérer certaines valeurs de Piwik :